Algoritma DBSCAN case study: Dataset Iris
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) adalah salah satu algoritma clustering dalam machine learning yang menggunakan konsep kepadatan data untuk mengelompokkan titik-titik yang berdekatan dalam suatu ruang berdimensi tinggi. Algoritma ini tidak memerlukan jumlah klaster sebelumnya dan dapat mengidentifikasi klaster yang memiliki kepadatan yang berbeda.
Berikut adalah langkah-langkah utama algoritma DBSCAN:
1. **Inisialisasi:** Pilih sebuah titik data acak yang belum dikunjungi.
2. **Cek Kepadatan:** Hitung jumlah titik data yang berada dalam jarak ε (epsilon) dari titik yang dipilih. Jika jumlah titik dalam jarak tersebut kurang dari suatu ambang batas (minimumPts), maka tandai titik tersebut sebagai noise atau batas (tergantung pada implementasi) dan lanjutkan ke langkah berikutnya. Jika jumlahnya mencukupi, lanjutkan ke langkah berikutnya.
3. **Ekspansi Klaster:** Tandai titik yang telah dihitung sebagai bagian dari klaster saat ini, dan cari semua titik yang terjangkau (reachable) dari titik tersebut dalam jarak ε. Iteratif ekspansi dilakukan untuk menemukan semua titik yang terhubung dalam klaster.
4. **Ulangi Proses:** Ulangi langkah-langkah di atas untuk semua titik dalam klaster yang baru ditemukan. Proses ini terus berlanjut hingga tidak ada lagi titik yang dapat ditambahkan ke klaster atau semua titik telah dikunjungi.
5. **Label Noise:** Semua titik yang tidak termasuk dalam klaster adalah noise atau batas, tergantung pada implementasi. Noise dapat dianggap sebagai titik yang berada di luar klaster.
Hasil dari DBSCAN terdiri dari klaster yang terbentuk dan titik-titik yang dianggap sebagai noise. Beberapa konsep penting dalam algoritma ini melibatkan definisi kepadatan dan ketidaklangsungan yang dikenal sebagai titik batas.
Parameter utama dalam DBSCAN adalah ε (epsilon), yaitu jarak maksimum di antara dua titik agar satu dianggap tetangga dari yang lain, dan minimumPts, yaitu jumlah minimum titik yang diperlukan untuk membentuk klaster.
Kelebihan DBSCAN termasuk kemampuannya mengatasi klaster yang tidak berbentuk bola (non-spherical) dan dapat mendeteksi noise. Namun, pemilihan parameter ε dan minimumPts bisa menjadi tantangan dan dapat mempengaruhi hasil clustering.
Berikut ini adalah Algoritma DBSCAN dengan implementasi kode program di Python menggunakan editor Anaconda Navigator:
from sklearn import datasets
import
matplotlib.pyplot as plt
from
sklearn.cluster import DBSCAN
from
sklearn.decomposition import PCA

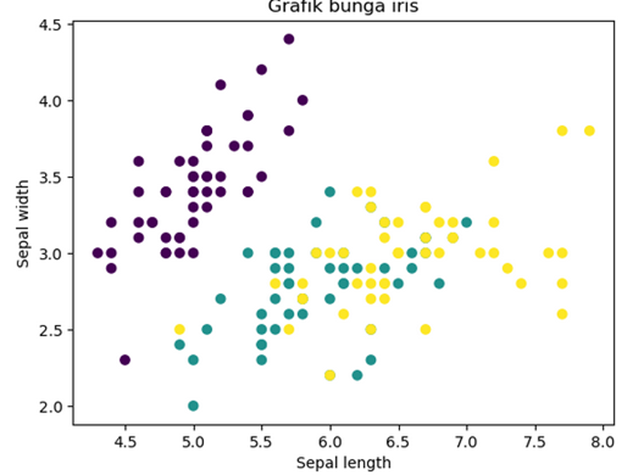
print(bunga.target_names)
x_axis =
bunga.data[:, 0] #sepal length
y_axis =
bunga.data[:, 1] #sepal width
#tampilkan data
plt.scatter(x_axis,
y_axis, c=bunga.target)
plt.xlabel("Sepal
length")
plt.ylabel("Sepal
width")
plt.title("Grafik
bunga iris")
plt.show()
Output kode program tersebut adalah:
#menggunakan
model DBSCAN
dbscan
= DBSCAN()
#fitting
data
dbscan.fit(bunga.data)
#Transformasi
menggunakan PCA 2 D
pca
= PCA(n_components=2).fit(bunga.data)
pca_2d
= pca.transform(bunga.data)
#Visualisasi
dengan scatterplot
label
= {0: 'red', 1: 'blue', 2: 'green'}
for
i in range(0, pca_2d.shape[0]):
if dbscan.labels_[i] == 0:
cluster1 = plt.scatter(pca_2d[i,
0],pca_2d[i, 1],c='r',marker='^')
elif dbscan.labels_[i] == 1:
cluster2 = plt.scatter(pca_2d[i,
0],pca_2d[i, 1],c='g',marker='.')
elif dbscan.labels_[i] == -1:
noise = plt.scatter(pca_2d[i,
0],pca_2d[i, 1],c='b',marker='X')
#Memberikan
legend dan judul
plt.legend([cluster1,
cluster2, noise], ['cluster 1','cluster 2','Noise'])
plt.title("Klasterisasi
Bunga Iris dengan DBSCAN")
plt.show()
Output dari kode program diatas adalah: