Clustering K-Means dengan Elbow method
Metode Elbow (elbow method) adalah sebuah teknik yang digunakan untuk membantu menentukan jumlah optimal dari klaster (cluster) dalam suatu algoritma clustering. Tujuan utamanya adalah untuk menemukan titik di mana penambahan jumlah klaster tidak memberikan peningkatan yang signifikan dalam kualitas pengelompokan data.
Berikut adalah langkah-langkah umum dalam menggunakan metode Elbow:
1. **Menjalankan Algoritma Clustering:** Terapkan algoritma clustering (seperti K-means) pada dataset dengan menggunakan berbagai nilai klaster. Misalnya, jalankan algoritma dengan jumlah klaster dari 1 hingga \(k_{\text{max}}\), di mana \(k_{\text{max}}\) adalah jumlah klaster maksimal yang ingin diuji.
2. **Hitung Variabilitas dalam Klaster (Inertia):** Setiap kali algoritma clustering dijalankan dengan jumlah klaster tertentu, hitung nilai inersia (inertia) klaster. Inersia biasanya diukur sebagai jumlah kuadrat jarak antara setiap titik data dan pusat klaster yang terdekat. Nilai inersia menggambarkan seberapa padat (compact) klaster-klasternya.
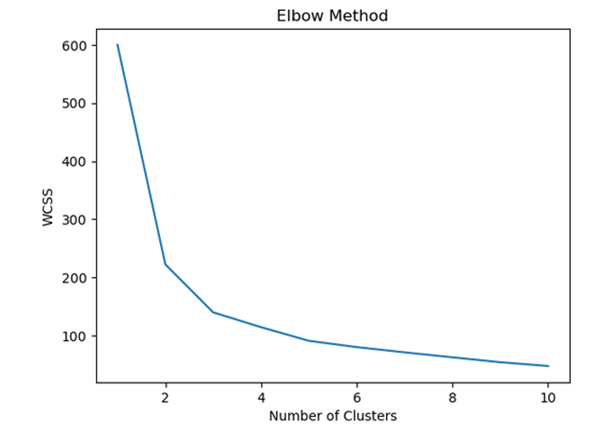
3. **Plot Nilai Inersia:** Plot nilai inersia untuk setiap jumlah klaster yang diuji. Dalam plot ini, sumbu x mewakili jumlah klaster, dan sumbu y mewakili nilai inersia. Hasilnya sering kali menyerupai bentuk "siku" (elbow).
4. **Identifikasi Titik Elbow:** Titik elbow adalah titik di mana penurunan inersia (nilai di sumbu y) menjadi lebih landai atau mencapai titik balik yang signifikan. Ini menunjukkan bahwa penambahan klaster setelah titik ini tidak memberikan penurunan inersia yang signifikan.
5. **Pemilihan Jumlah Klaster Optimal:** Pilih jumlah klaster yang sesuai dengan titik elbow sebagai jumlah optimal klaster untuk model clustering.
Metode Elbow memberikan panduan intuitif untuk menentukan jumlah klaster yang optimal. Namun, penting untuk diingat bahwa dalam beberapa kasus, bentuk "elbow" mungkin tidak selalu jelas, dan interpretasi subjektif dari hasil tersebut mungkin diperlukan. Selain itu, keberhasilan metode ini juga dapat bergantung pada distribusi data dan karakteristik algoritma clustering yang digunakan.
Berikut ini adalah contoh implementasi dalam bahasa pemrograman Python:
from sklearn import datasets
from
sklearn.cluster import KMeans
from
sklearn.preprocessing import StandardScaler
import
matplotlib.pyplot as plt
iris =
datasets.load_iris()
features =
iris.data
# Standardize
the features
scaler =
StandardScaler()
features_standardized
= scaler.fit_transform(features)
wcss = []
for i in
range(1, 11):
kmeans = KMeans(n_clusters=i,
init='k-means++', max_iter=300, n_init=10, random_state=0)
kmeans.fit(features_standardized)
wcss.append(kmeans.inertia_)
# Plot the WCSS
values for different numbers of clusters
plt.plot(range(1,
11), wcss)
plt.title('Elbow
Method')
plt.xlabel('Number
of Clusters')
plt.ylabel('WCSS')
plt.show()
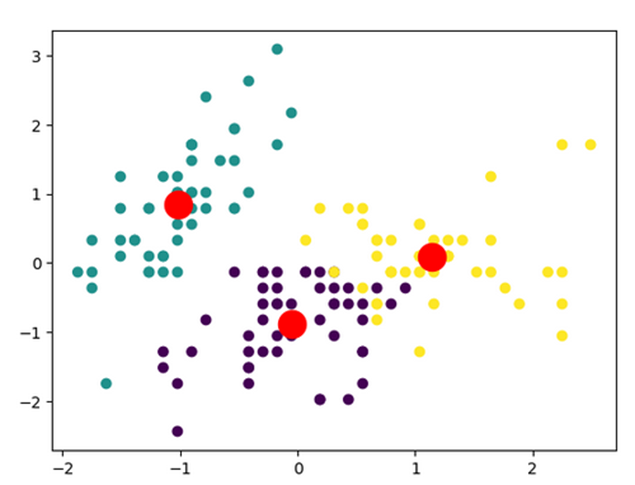
kmeans =
KMeans(n_clusters=3, init='k-means++', max_iter=300, n_init=10, random_state=0)
pred_y =
kmeans.fit_predict(features_standardized)
plt.scatter(features_standardized[:,
0], features_standardized[:, 1], c=pred_y)
plt.scatter(kmeans.cluster_centers_[:,
0], kmeans.cluster_centers_[:, 1], s=300, c='red')
plt.show()
Output dari program diatas adalah: