Clustering K-Means dengan Silhouette Method dan Implementasi coding di Python
Metode silhouette (silhouette method) adalah sebuah teknik yang digunakan untuk mengevaluasi seberapa baik sebuah model clustering telah melakukan pengelompokan pada data. Metode ini memberikan ukuran numerik terhadap seberapa dekat setiap titik data dalam suatu klaster dengan klaster lainnya.
Berikut adalah langkah-langkah umum dari metode silhouette:
1. **Hitung Jarak dalam Klaster (a_i):** Hitung rata-rata jarak antara setiap titik data dalam suatu klaster dengan semua titik data lainnya di dalam klaster yang sama. Ini menggambarkan seberapa compact (padat) klaster tersebut.
2. **Hitung Jarak antar Klaster Terdekat (b_i):** Hitung rata-rata jarak antara setiap titik data dalam suatu klaster dengan semua titik data dalam klaster terdekat (klaster selain klaster yang titik data tersebut berada). Ini memberikan gambaran tentang seberapa terpisah klaster tersebut dari klaster lainnya.
3. **Hitung Silhouette Score (S_i):** Silhouette score untuk setiap titik data dapat dihitung menggunakan rumus berikut:
\[ S_i = \frac{{b_i - a_i}}{{\max(b_i, a_i)}} \]
Silhouette score berkisar antara -1 hingga 1. Nilai positif menunjukkan bahwa titik data tersebut lebih dekat dengan klasternya sendiri daripada dengan klaster tetangga, sedangkan nilai negatif menunjukkan sebaliknya.
4. **Hitung Silhouette Score Rata-rata (S):** Hitung nilai rata-rata dari semua silhouette score. Ini memberikan ukuran keseluruhan seberapa baik model clustering bekerja pada dataset tersebut.
5. **Interpretasi Hasil:** Nilai silhouette score yang mendekati 1 menunjukkan bahwa observasi tersebut berada dalam klaster yang sesuai, sedangkan nilai yang mendekati -1 menunjukkan bahwa observasi tersebut mungkin telah ditempatkan dalam klaster yang salah.
Metode silhouette membantu peneliti atau praktisi machine learning untuk mengevaluasi kualitas klaster yang dihasilkan oleh algoritma clustering tertentu. Nilai silhouette yang tinggi menunjukkan bahwa klaster-klasternya bersifat padat dan terpisah dengan baik, sementara nilai yang rendah menandakan adanya tumpang tindih antar klaster atau mungkin kesalahan dalam pengelompokan.
Berikut contoh implementasi Clustering dengan K-Means menggunakan metode silhouette dalam bahasa pemrograman Python:
from sklearn
import datasets
from
sklearn.cluster import KMeans
from
sklearn.preprocessing import StandardScaler
from
scipy.spatial.distance import cdist
import
matplotlib.pyplot as plt
#import
matplotlib.pyplot as plt
iris =
datasets.load_iris()
features =
iris.data
plt.scatter(features[:,0],
features[:,1])
plt.show()
ketika di RUN dari potongan scurpt diatas, maka akan tampil output sebagai berikut:

#Menstandardisasi
fitur
scaler =
StandardScaler()
features_standardized
= scaler.fit_transform(features)
from
sklearn.metrics import silhouette_samples, silhouette_score
from
sklearn.cluster import KMeans
import
matplotlib.pyplot as plt
wcss = []
for i in
range(1, 11):
kmeans = KMeans(n_clusters=i,
init='k_means++', max_iter=300, n_init=10, random_state=0)
kmeans.fit(features)
wcss.append(kmeans.inertia_)
plt.plot(range(1, 11), wcss)
plt.title('Elbow Method')
plt.xlabel('Number of Clusters')
plt.ylabel('WCSS')
plt.show()
##Versi ChatGPT
from sklearn.metrics
import silhouette_samples, silhouette_score
from
sklearn.cluster import KMeans
import
matplotlib.pyplot as plt
wcss = []
for i in
range(1, 11):
kmeans = KMeans(n_clusters=i,
init='k-means++', max_iter=300, n_init=10, random_state=0)
kmeans.fit(features)
wcss.append(kmeans.inertia_)
# Plot the WCSS
values for different numbers of clusters
plt.plot(range(1,
11), wcss)
plt.title('Elbow
Method')
plt.xlabel('Number
of Clusters')
plt.ylabel('WCSS')
plt.show()
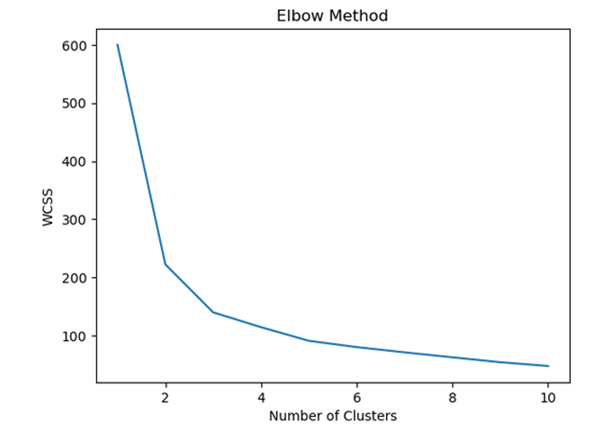
Ketika di RUN kembali, maka akan tampil output sebagai berikut:

##Melakukan
Clustering versi ChatGPT
from
sklearn.cluster import KMeans
import
matplotlib.pyplot as plt
pred_y =
kmeans.fit_predict(features)
plt.scatter(features[:,
0], features[:, 1])
plt.scatter(kmeans.cluster_centers_[:,
0], kmeans.cluster_centers_[:, 1], s=300, c='red')
Output dari kode program lengkap diatas, adalah :