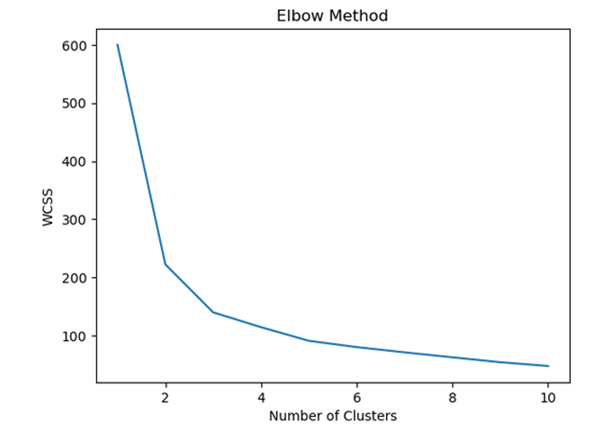
Algoritma DBSCAN case study: Dataset Iris

DBSCAN (Density-Based Spatial Clustering of Applications with Noise) adalah salah satu algoritma clustering dalam machine learning yang menggunakan konsep kepadatan data untuk mengelompokkan titik-titik yang berdekatan dalam suatu ruang berdimensi tinggi. Algoritma ini tidak memerlukan jumlah klaster sebelumnya dan dapat mengidentifikasi klaster yang memiliki kepadatan yang berbeda. Berikut adalah langkah-langkah utama algoritma DBSCAN: 1. **Inisialisasi:** Pilih sebuah titik data acak yang belum dikunjungi. 2. **Cek Kepadatan:** Hitung jumlah titik data yang berada dalam jarak ε (epsilon) dari titik yang dipilih. Jika jumlah titik dalam jarak tersebut kurang dari suatu ambang batas (minimumPts), maka tandai titik tersebut sebagai noise atau batas (tergantung pada implementasi) dan lanjutkan ke langkah berikutnya. Jika jumlahnya mencukupi, lanjutkan ke langkah berikutnya. 3. **Ekspansi Klaster:** Tandai titik yang telah dihitung sebagai bagian dari klaster saat ini, dan cari semua titi...